

目的
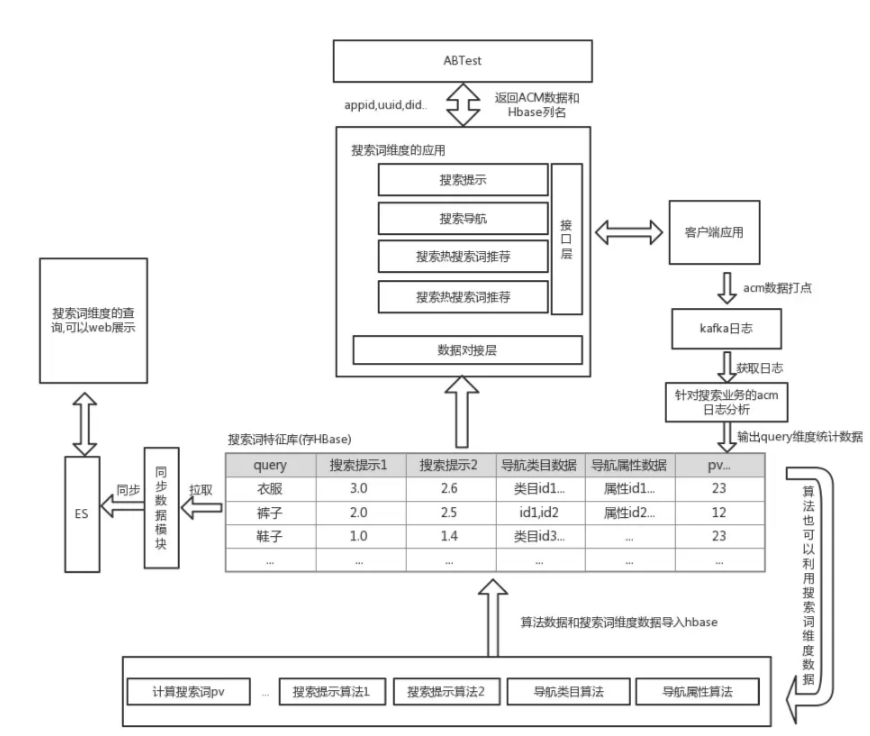
目前搜索业务除了搜商品之外,天辰软件下载我总结为都是输入为query,输出为依据query引荐的信息。比方"搜索导航"输出的是一堆类目id和属性id, "搜索提示"输出的是query相关依据算法提供的score排序, "热搜词"输出的是与query相关的抢手搜索, "你可能会搜产品"输出的是对应中心词。这些产品能够统一成一张以query词key,collum为算法输出的query特征Hbase表。在这张表中,除了存储一些算法数据,还能够插入query维度的相关特征信息比方pv;uv;gmv等。 依据这张表, 我能很便当的管理算法的abtest功用,搜索词的数据统计功用,一切搜索词相关产品工程完成能够对接这张表,算法开发的搜索词的根底数据也能够接入这张表。
搜索相关算法产品的query为网站的历史搜索词, 能够经过添加列添加对应的内容。由于Hbase 面向列存储的,能够横向扩展,只需有query维度的算法产品需求,我们能够添加一列,算法工程师能够把query对应的值存在这个列中。这样关于搜索业务开发取对应的算法数据十分便当。在这个搜索词特征表的根底下,想象的算法出数据,工程组装数据并展现给用户的流程如下:
为什么需求搜索词特征表
以前接到搜索词维度的需求是,天辰平台挂机软件下载都是算法产出的数据经过人肉的办法(热搜词引荐,xxx通知我redis地址或者接口)给工程人员,获取痛快工程人员本人维护一份算法数据(导航和搜索提示)。这样的结果是,开发过程是十分高效的单兵作战, 但是后期有算法人员需求优化的时分,就会研讨整个详细的工程(比方svn up一个搜索提示的工程,然后开端debug),这样并不合适快速算法更新迭代。假设采用上述的方式,算法开发只需求对接Hbase表, 依据对算法工程师的调研,他们产生最终算法数据生成一个文件给我,和把这些数据插入到Hbase的本钱是一样的。那么从搜索业务工程师的角度而言,只需理解算法产品对应的Hbase列,那么导航、搜索提示等搜索词维度工程的初始化操作也都是统一的,那就是从表中select某个列,然后开端处置。
关于搜索词的算法产品, 简直都需求搜索词的pv,uv,gmv数据。 上一节提到算法开发能够很便当的输出到搜索词特征表, 那么我们把这些数据存在这张表, 算法工程师的输入也能够来自这张表, 这对算法开发的工作也很有协助。我理解到算法团队普通用spark跑算法数据,这样做的结果是spark工程中的输入和输出都是同一个中央,能够简少代码维护工作。这样做的结果如下:
其他衍生功用
假如算法开发有abtest需求, 搜索词工程(搜索提示,导航)处置之前能够获取abtest配置信息,这个配置信息包括走哪个算法(对应Hbase列),还包括打点信息(自定义参数)。从kafka日志系统获取这些打点数据剖析后,能够计算出该搜索词在该算法下的表现如何。这个表现结果还是插入到搜索词特征表,那么算法的总体表现能够经过特征表画出曲线图看到算法结果。
网友回应